
About the author:
Oleksandr Oliinyk is a Ruby / NodeJS Developer at Syndicode and a Team Lead of a project that has microservice architecture. The application contains different services written on Ruby and NodeJS, several PostgreSQL databases, ElasticSearch, Amazon S3, Stripe, and others.
Scraper is an application that fetches data from another application.
But, what if your source is a popular resource that has an anti-bot system, access restrictions? And you need much information? In this article, we’re going to describe the way of building the NodeJS web scraper.
Main requirements:
- High performance
- Fail-safe
- Configurable
Solutions:
- Start the application on several servers to improve performance
- Using queues to provide fault tolerance
Example:
Let’s imagine a source where there are users who have some items. Like a marketplace where there are sellers and products or social media with users and posts. You can fetch 10 users per minute from 1 IP address. You need to download at least 100 000 users with their items each day.
1. Setup a queue. (queue.js)
const kue = require('kue-unique')
const queue = kue.createQueue({
prefix: 'scraper',
redis: process.env.REDIS_URL,
})
process.once('SIGTERM', (sig) => {
// for debugging
console.log('SIGTERM', sig)
})
process.once('uncaughtException', (error) => {
// for debugging
console.error(`uncaughtException: ${error.message}`)
})
// first worker is main
if (process.env.WORKER === '0') {
kue.app.listen(process.env.PORT)
queue.on('job error', (id, type) => {
// Here you can catch error from all workers
// if (type.includes('unique constraint')) console.error(`job error: ${id}`, type)
})
queue.watchStuckJobs(5000)
// restart previously active jobs on start
queue.active((err, ids) => {
ids.forEach((id) => {
kue.Job.get(id, (_err, job) => {
// Your application should check if job is a stuck one
if (job && job.inactive) job.inactive()
})
})
})
//restart failed jobs on start (if needed)
queue.failed((err, ids) => {
ids.forEach((id) => {
kue.Job.get(id, (_err, job) => {
// Your application should check if job is a stuck one
if (job && job.inactive) job.inactive()
})
})
})
}
module.exports = queue2. Setup proxy router (proxy.router.js)
Each worker has its own proxy servers. It excepts the possibility of sending a request from different workers but with the same proxy. Here is a simple implementation. On production, you should move the list of proxies to your database or some other safe place.
const PROXY_RANGE_PER_WORKER = 2
class ProxyRouter {
constructor() {
this.cursor = -1
this.minCursor = parseInt(process.env.WORKER || '0') * PROXY_RANGE_PER_WORKER
this.maxCursor = this.minCursor + PROXY_RANGE_PER_WORKER
}
next() {
this.cursor += 1
if (this.cursor > this.maxCursor) {
this.cursor = this.minCursor
}
if (ProxyRouter.servers[this.cursor]) {
console.log('ProxyRouter: ', this.cursor, ProxyRouter.servers[this.cursor])
return ProxyRouter.servers[this.cursor]
}
return this.next()
}
}
ProxyRouter.servers = [
'login:password@192.168.0.1:46833',
'login:password@192.168.0.2:46833',
]
module.exports = new ProxyRouter()3. Setup the main class responsible for fetching and saving data (user.updater.js)
const _ = require('lodash')
const bluebird = require('bluebird')
const axios = require('axios')
const HttpsProxyAgent = require('https-proxy-agent')
const moment = require('moment')
const pgPool = require('lib/pg.pool')
const proxyRouter = require('lib/proxy.router')
const USER_VALID_PERIOD = 24
const DELAY_BEFORE_REQUEST = 5
class UserUpdater {
constructor({ id }) {
this.id = id
this.dbUser = null
this.user = null
this.httpsProxyAgent = null
}
async call() {
console.log(`"${this.id}" has been started`)
await this._getDBUser()
if (this._isDBUserFresh()) {
console.log(`"${this.id}" is fresh`)
return
}
this._setHttpsProxyAgent()
await this._fetchUser()
// if we got no error and there is no user data then just silently stop
if (!this.user) return
if (this.dbUser) {
await this._updateDBUser()
} else {
await this._saveDBUser()
}
console.log(`"${this.id}" has been finished`)
}
async _getDBUser() {
const query = {
text: `SELECT id, email, updated_at
FROM users
WHERE id = $1
LIMIT 1`,
values: [this.id],
}
const { rows } = await pgPool.query(query)
this.dbUser = rows[0]
if (this.dbUser) {
console.log(`"${this.id}" is present in db`)
} else {
console.log(`"${this.id}" is absent in db`)
}
}
_isDBUserFresh() {
if (!this.dbUser) return true
const edgeDate = moment()
.subtract(USER_VALID_PERIOD, 'hour')
.toDate()
return this.dbUser.updated_at < edgeDate
}
async _setHttpsProxyAgent() {
this.httpsProxyAgent = new HttpsProxyAgent(`http://${proxyRouter.next()}`)
}
async _fetchUser() {
try {
// make requests a bit chaotic in time
await bluebird.delay(DELAY_BEFORE_REQUEST + (5000 * Math.random()))
const response = await axios.request({
url: `https://www.source.com/${this.id}`,
httpsAgent: this.httpsProxyAgent,
})
this.user = JSON.parse(response.data)
} catch (e) {
if (_.get(e, 'response.status') === 404) {
console.log(`"${this.id}" 404`)
// we don't need to throw the error in this case
} else if (_.get(e, 'response.status') === 429) {
console.log(`"${this.id}" 429`)
// throw the error to repeat the job later
throw e
} else {
throw e
}
}
}
async _updateDBUser() {
const query = {
text: `UPDATE users
SET
full_name = $1,
image = $2,
email = $3,
updated_at = now()
WHERE
id = $4 RETURNING id`,
values: [
this.user.fullName,
this.user.image,
this.user.email,
this.dbUser.id,
],
}
await pgPool.query(query)
console.log(`"${this.id}" has been updated in db`)
}
async _saveDBUser() {
const query = {
text: `INSERT INTO
users(id,
full_name,
image,
email,
created_at,
updated_at)
VALUES
($1, $2, $3, $4, now(), now()) RETURNING id`,
values: [
this.id,
this.user.fullName,
this.user.image,
this.user.email,
],
}
await pgPool.query(query)
console.log(`"${this.id}" has been saved in db`)
}
}
module.exports = UserUpdater4. Setup initializer (jobs.initializer.js)
Here I want to explain the main idea of parallelism. Library “kue” is not perfect (or I just don’t understand something). If you want to have a lot of workers with several threads in each of them, you’ll face an issue when 2 workers take the same job. So, I decide to separate queues, so each worker has its own. Whether workers should be as independent as possible, in my case, a worker fills its queue itself, but you can extract this logic to one worker that would fill all queues.
const queue = require('utils/queue')
const UserUpdater = require(lib/user.updater')
function queueUserUpdater() {
queue.process(`UserUpdater${process.env.WORKER}`, async (job, ctx, done) => {
const userUpdater = new UserUpdater(job.data)
try {
await userUpdater.call()
done()
} catch (e) {
done(e)
}
})
console.log(`Queue "UserUpdater${process.env.WORKER}" has been set up`)
}
module.exports = () => {
queueUserUpdater()
}Summary
NodeJS is perfect for scraping because it requires not much memory and has all the needed libraries. Its event loop system allows enabling several threads per worker. Later it’s easy to add an admin panel, to be able to configure the app in real-time and show statistics.
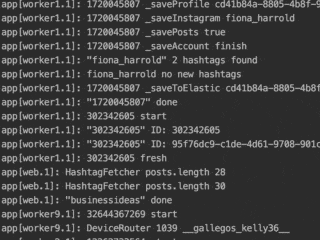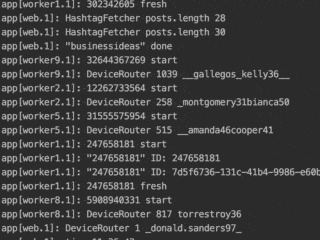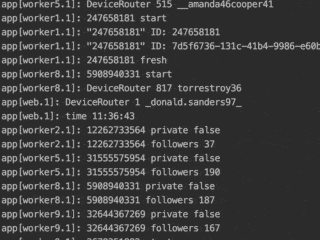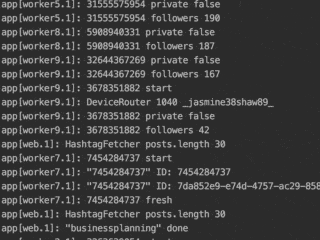
From my personal experience, it’s ok to deploy a new logic frequently and observe the behavior of the scraper on your servers. Write informative logs that allow you to catch errors. Write down data into your DB so you can understand the performance of the scraper.
NodeJS web scraper is the best option nowadays for these goals.
Wait for my next article about Instagram ?
p.s. Subscribe to Syndicode newsletter to get all the interesting news right to your mailbox!
Or just hire a professional team of Node.js developers who are always aware of the latest trends and know how to unleash the full potential of the Node.js programming language.