
According to the Paper Diet report a misplaced document can cost a company $125 in lost productivity. It is a solid reason to digitize your paper-based processes if you have not done this before.
That’s when OCR image processing software saves the day. So if document digitization is a pressing issue for your company, we recommend that you build your own OCR system to get a unique solution tailored to the specific needs of your organization.
What & How OCR works?
We use the term optical character recognition or OCR for short to define the technology that is used to recognize a printed or handwritten text inside an image and convert it into an electronic form for further data processing, as in searching or editing.
Businesses can derive the following benefits from using OCR systems:
- Reduction of data entered manually
- Acceleration of working processes
- Elimination of errors
- Data centralization and security
- Increased productivity
- Saving costs on document digitization
- The ability to reallocate the physical storage space
In this article, we will discuss the most common and efficient approaches to OCR image processing and show how you can implement them on your own.
Types of documents to digitize
These days companies most commonly digitize the most important documents related to their operational activities, such as bills and invoices, official correspondences, receipts, financial statements, contracts, etc.
However, today we will delve into the business card recognition process. Wonder why? The thing is that this document is considered one of the most complicated ones for recognition since it contains lots of various data including name, address, phone number, email address.
Here we should mention that each business card has a unique design. It makes the OCR text recognition much more difficult.
The problem
The main problem is people have to enter information from the Visit Cards manually. And we wanted to create a business card reader that will allow us to use iOS devices’ cameras to extract Visit Cards’ owner name, email and the country name. And, possibly, other data on demand.
The solution can be split in several stages:
- Detect the visit card itself
- Detect the text on the visit card
- Get all the necessary information from the text
- Verify that we’ve recognized things we need
Recognition pipeline
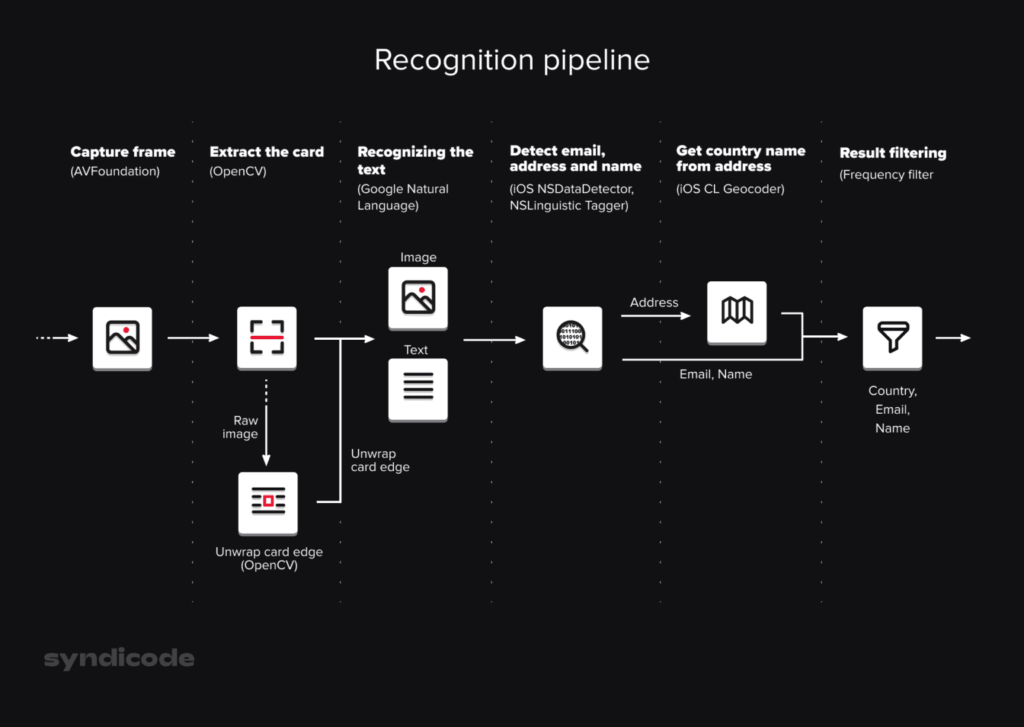
1. Capture frame
First we need to capture the video frame by frame from the camera. We create AVSession with the output that captures the video data:
- (AVCaptureSession*)startSessionWithInput:(AVCaptureDeviceInput*)input
{
AVCaptureSession* session = [[AVCaptureSession alloc] init];
AVCaptureVideoDataOutput* videoOutput = [AVCaptureVideoDataOutput new];
NSString* key = (__bridge NSString*)kCVPixelBufferPixelFormatTypeKey;
videoOutput.videoSettings = @{ key : @(kCVPixelFormatType_32BGRA) };
[videoOutput setSampleBufferDelegate:self queue:self.videoProcessingQueue];
return session;
}Capture frame needed to split video into frames sequence:
- (void)captureOutput:(AVCaptureOutput*)output
didOutputSampleBuffer:(CMSampleBufferRef)sampleBuffer
fromConnection:(AVCaptureConnection*)connection
{
CVImageBufferRef imageBuffer = CMSampleBufferGetImageBuffer(sampleBuffer);
CVPixelBufferLockBaseAddress(imageBuffer, 0);
Sample sample;
size_t bpr = CVPixelBufferGetBytesPerRow(imageBuffer);
sample.width = CVPixelBufferGetWidth(imageBuffer);
sample.height = CVPixelBufferGetHeight(imageBuffer);
sample.bpp = bpr / sample.width;
sample.data = CVPixelBufferGetBaseAddress(imageBuffer);
sample.orientation = connection.videoOrientation;
// Process sample
CVPixelBufferUnlockBaseAddress(imageBuffer, 0);
}Where the Sample is our custom structure to bridge between Objective-C and C++ code:
typedef struct
{
size_t width;
size_t height;
size_t bpp;
AVCaptureVideoOrientation orientation;
const void* data;
} Sample;2. Extract the card from the raw image
Once we have raw image data we want to detect all the text on it. But here we have 2 issues:
- If the text is not placed horizontally, it’s recognition quality is much lower
- We may have a lot of unnecessary text on the background, and we don’t want to spend time on its recognition in the real time
To solve this problem we can detect the rectangular frame of the Visit Card, cut it out from the raw image and unwrap it horizontally. Let’s use OpenCV for this
First let’s prepare the image for edge detection:
- Make it grayscale to increase the performance (1 channel processing is faster than 3)
- Apply unsharp mask filter to make edges more sharp
- Apply pyramid filter to get rid of small details
// Make it grayscale
cv::cvtColor(img, gray, cv::COLOR_BGR2GRAY);
// Unsharp mask aka inverse gaussian blur
t0 = img.clone();
t1 = img.clone();
cv::GaussianBlur(img, t0, cv::Size(15, 15), 0);
cv::subtract(img, t0, t1);
// Pyramid filter
cv::Mat pyr;
cv::Mat timg;
cv::Mat res;
cv::pyrDown(img, pyr, cv::Size(img.cols/2, img.rows/2));
cv::pyrUp(pyr, res, img.size());Now let’s extract edges:
- Apply Canny filter to find edges
- Dilate contours to get rid of too small contour details, since we’re looking for big rectangles
cv::Canny(res, gray, 0, thresh, 5);
cv::dilate(gray, gray, cv::Mat(), cv::Point(-1, -1));
std::vector< std::vector<cv::Point> > contours;
cv::findContours(gray, contours, RetrievalModes::RETR_LIST,
ContourApproximationModes::CHAIN_APPROX_SIMPLE);After that we can pick the best contour matching following criteria:
- It covers the center or close to it
- It’s convex
- It’s close to rectangle, with aspect in some range
- It’s rather big
Now we have a contour, 4 vertices for quad bounding the card. For it we can build a matrix to transform the visit card area into aligned separated rectangular image
std::vector<cv::Point2f> src;
src.push_back(best.vertex(0));
src.push_back(best.vertex(1));
src.push_back(best.vertex(2));
src.push_back(best.vertex(3));
std::vector<cv::Point2f> dst;
dst.push_back(dest.vertex(0));
dst.push_back(dest.vertex(1));
dst.push_back(dest.vertex(2));
dst.push_back(dest.vertex(3));
Mat warpMatrix = cv::getPerspectiveTransform(src, dst);
cv::Mat rotated;
warpPerspective(img, rotated, warpMatrix, size,
INTER_LINEAR, BORDER_CONSTANT);Eventually we get something like that:

3. Recognizing the text
Now when we have an unwrapped visit card we can easily detect text on it. For this we can use Google Natural Language library. It’s the best available offline solution to recognize English text
FIRVision* vision = [FIRVision vision];
FIRVisionTextRecognizer* rec = [vision onDeviceTextRecognizer];
[rec processImage:img
completion:^(FIRVisionText* text, NSError* error) {
// Here we have a recognized text
}];Here is what we get for the particular image:

Stanford University
75 Alta Road
Stanford, CA 94305
T650.736.2290 (office admin)
F650.736.2460
amil@stanford.edu
http://med.stanford.edu/cerc.html
https:/aicare.stanford.edu/
ARNOLD MILSTEIN
Professor and Director
Clinical Excellence
Research Center4. Detect email, address and name
Once we have the text from the card we can use iOS built-in libraries to get address, organization name and URLs (since email is kind or URL in Apple’s opinion). Here is how we can achieve this. First let’s search for names with NSLinguisticTagger:
NSArray* s = @[NSLinguisticTagSchemeNameType];
NSLinguisticTagger* tagger = [[NSLinguisticTagger alloc] initWithTagSchemes:s
options:0];
NSArray* tags = @[NSLinguisticTagPersonalName,
NSLinguisticTagPlaceName,
NSLinguisticTagOrganizationName];
tagger.string = s;
NSRange r = NSMakeRange(0, [s length]);
NSUInteger options = NSLinguisticTaggerOmitPunctuation |
NSLinguisticTaggerOmitWhitespace |
NSLinguisticTaggerJoinNames;
[tagger enumerateTagsInRange:r
unit:NSLinguisticTaggerUnitWord
scheme:NSLinguisticTagSchemeNameType
options:options
usingBlock:^(NSLinguisticTag tag,
NSRange tokenRange,
BOOL* stop)
{
// Here we have a result
}];After it let’s search for links and addresses with NSDataDetector:
NSUInteger types = NSTextCheckingTypePhoneNumber |
NSTextCheckingTypeAddress |
NSTextCheckingTypeLink;
NSRange r = NSMakeRange(0, [s length]);
NSDataDetector* detector = [NSDataDetector dataDetectorWithTypes:types
error:&error];
NSArray* matches = [detector matchesInString:s
options:0
range:r];5. Get country name from address
We’re almost there. Point is the address is always written in freestyle. For example, the United States can be written as US, USA, United States, United States of America etc. Plus, some addresses may not include the country at all, however it’s clear that they belong to a particular country. To deal with this we can use a geocoding service. Apple’s Core Location allows to turn the address into a placemark which contains ISO country code.
CLGeocoder* geocoder = [[CLGeocoder alloc] init];
[geocoder geocodeAddressString:fullAddress
completionHandler:^(NSArray<CLPlacemark*>* placemarks,
NSError* error)
{
// placemarks.firstObject.ISOcountryCode is what we need
}];For this image the address is “75 Alta Road Stanford, CA”, but we don’t have an explicit mention of a country:

But this address is totally enough for geocoder to find a location. And this location has ISO country alpha-2 code:
75 Alta Road Stanford CA => US6.Result filtering
Now we actually parsed all the data. But the problem is every pipeline iteration gives us a bit different result. It can be caused by camera shake, illumination changes, interference in text recognition of designer’s text etc. But if we add a frequency filter for name, country and email we can pick the most stable result among recent ones. Which gives us a pretty nice accuracy in live recognition:

Conclusion
Current approach for OCR text recognition has some restrictions:
- It works well only for English. Google NL works not so great with other languages. Plus the iOS linguistic analyzer and data detector created for the USA data formats mainly
- The accuracy of organizations’ names recognition is very low
- Custom designed text on scanned business cards is poorly recognized
- Current algorithm supposes portrait orientation and near-horizontal orientation on the card
- Edges detection algorithm is far from being perfect and still has a room for improvement
- Geocoding requires the Internet for stable working
- Performance and energy impact is very high, hence scanning within long period of time will drain battery
- OpenCV contour detection sometimes raises exceptions. It’s a rare case, so we can turn a blind eye on it. To fix this bug I’ll need to debug OpenCV sources and compile it again
- Dependencies add +10Mb to the binary size
However, the solution appeared to be just good enough for solving the particular problem, which is OCR image processing of business cards. It works fast enough on any device not older than iPhone 6s and provides a good recognition accuracy in proper lighting conditions. Plus, it recognizes the email in 99.5% cases, which is already a good achievement
Solution can be improved and extended in case of necessity:
- Google NL and iOS recognizers support many other languages
- Orientation detector can be improved to detect visit cards in any orientation
- Edges recognition algorithm can be significantly improved which will lead to much higher unwrap performance and accuracy
- Using of Google Maps geocoder will make country detection much more accurate, especially outside the United States
- We’re using about 1% of OpenCV capabilities, hence we can build it with only required functionality, it will save several megabytes