
People no longer fear that machines will take over their jobs. Instead, they expect AI features to be present in every software product to enhance human capabilities. This isn’t just a trend; it’s become essential.
However, the performance, accuracy, and dependability of AI models, especially those driven by ML and deep learning, hinges on the quality of their training data.
This article will discuss why data matters in AI and ML software development, how to collect relevant data for different tasks, and what you can do to ensure your data meets the necessary standards for a reliable AI/ML algorithm.
Before diving in, let us introduce ourselves. Syndicode is a full-service digital transformation partner with over a decade of experience in custom software creation. Our expertise spans from the initial concept to post-launch maintenance, including design, development, and generative AI integration.
Among our latest AI-enhanced projects there is Le New Black, an iPad wholesale trade management tool that automatically captures client information from business cards.
We also invite you to read an insightful article on computer vision development by one of our senior engineers.
Understanding the role of data in AI development

AI systems work by using large sets of data and intelligent algorithms that iteratively learn from patterns and features within the data. Each time the system processes data, it evaluates its performance and gains new insights. Once it meets specific success criteria, it becomes ready for deployment.
Consider an AI-powered business card reader as an example. To develop it, we feed the system a variety of business cards in different formats, fonts, and layouts. The algorithm then identifies text locations and interprets the content, improving its accuracy in recognizing names, phone numbers, addresses, and other details across various designs.
We assess its accuracy with new data to determine if further training is necessary. Often, multiple iterations are required to eliminate errors.
As you can see from this example, data is central to creating AI applications. Therefore, the emphasis in AI development should be on acquiring, refining, and managing high-quality data.
In need of an AI development team?
Syndicode offers end-to-end AI development services, covering every aspect of AI and ML-powered software development—from initial planning to post-launch support. Visit our dedicated page for a full overview of our services.
See servicesTypes of data used for AI development
AI development serves a range of purposes, from understanding spoken language and providing customer support to managing automated stock trades. Each AI application requires different types of data for training and faces its own challenges and opportunities for analyzing and interpreting this data.
Here’s how AI developers categorize data:
- Structured data is neatly organized in a specific format, like tables, spreadsheets, or databases. It’s often used in machine learning for tasks such as sorting, predicting, and grouping.
- Unstructured data doesn’t follow a specific format or organization. This includes texts, images, audio, and videos. Techniques in natural language processing (NLP) and computer vision are applied to handle this type of data.
- Semi-structured data is a mix of structured and unstructured data, with some level of organization, like JSON or XML files. It’s typically used in web scraping and data exchange.
- Time-series data records observations over regular time intervals. This type of data is crucial in fields like finance, the IoT, healthcare, and manufacturing for forecasting and detecting trends or anomalies.
- Textual data includes all forms of written words. It’s essential for NLP tasks like analyzing sentiments, classifying texts, recognizing entities, translating languages, operating chatbots, and summarizing documents.
- Image data captures visual information through cameras or imaging devices. It supports computer vision tasks such as identifying objects, classifying images, recognizing faces, analyzing medical images, driving autonomous vehicles, and assessing satellite images.
- Audio data captures sounds through microphones or audio devices. It’s used for recognizing speech, identifying speakers, detecting emotions, analyzing music, powering voice assistants, and monitoring audio.
- Sensory data comes from physical sensors like temperature sensors, accelerometers, and gyroscopes. This data is vital for IoT, wearables, industrial automation, smart buildings, health monitoring, and environmental surveillance.
Sources of data for AI development
When selecting data for your AI development project, the type of data you need will influence which sources are most beneficial. Note that it’s critical to incorporate data from multiple sources to minimize bias and enhance the algorithm’s decision-making capabilities.
Here are the primary sources AI developers utilize to collect data:
- Public datasets are freely available data collections that are openly shared for research, analysis, and educational use. They offer AI developers a wealth of data across various fields without the need for direct data collection, supporting machine learning research, algorithm benchmarking, predictive model training, and trend analysis.
- Internal data is what organizations generate or gather through their operations, transactions, or interactions with customers, employees, or partners. Examples include customer databases, sales records, financial statements, and operational metrics. This data is useful for customer relationship management, sales predictions, supply chain improvements, fraud detection, and automation processes.
- Web scraping automatically extracts data from websites and web pages, capturing text, images, links, metadata, and structured web content. It’s applied to collect product details, news, job listings, social media content, and other online information for analysis and monitoring.
- APIs and online services provide easy access to a variety of data sources, such as social media platforms (e.g., Twitter API) and financial information (e.g., Bloomberg API), enabling developers to incorporate external data into AI applications effortlessly.
- IoT devices and sensors collect data from physical objects and environments, which can be used in applications like smart homes, industrial automation, health monitoring, environmental tracking, and smart cities.
- Crowdsourcing enlists a large group of people to perform tasks or gather data, often via online platforms. It’s used for tasks that require human input, such as data labeling, content moderation, sentiment analysis, and collecting user feedback.
- Synthetic data is artificially created data that simulates real-world data properties and distributions. It’s generated through simulations, generative models, or data augmentation to tackle data scarcity, privacy, and ethical issues in AI development.
- Transactional data includes records of transactions or interactions between entities, like purchases and reservations. It is pivotal for customer analytics, recommendation systems, fraud detection, and personalized marketing.
- Multimedia content comprises digital media forms like images, videos, audio, and animations. It is used in content recommendations, surveillance, image recognition, augmented reality, and entertainment.
- Social media and forums offer sources of user-generated content. They facilitate analysis of sentiments, trends, marketing strategies, brand monitoring, crisis management, and social networking studies.
Need high-quality data for AI development?
Our team specializes in gathering and processing the right data for your needs, ensuring the creation of precise and effective AI models. Check our data mining services to see how we can help you.
ExploreHow data helps unlock insights through AI development
AI-driven functionalities and software have become essential in diverse industries. We most frequently encounter them in customer service, social media platforms, and voice assistants. Although equally vital and beneficial, these applications use distinct AI and ML technologies and require specific datasets for their development.
Let’s explore further.
Data in predictive analytics development
Predictive analytics models use historical data to forecast future events. Examples of well-known companies using these models to enhance their operations include:
- Amazon uses predictive analytics to analyze customers’ past browsing and purchasing habits, predicting future interests and recommending products they might like.
- Netflix relies on AI-driven predictive analytics for its recommendation system. Moreover, this technology guides content investments, acquisitions, and pricing strategies across different markets and user groups. Netflix also uses it to identify subscribers who are likely to cancel and offer them personalized promotions.
- American Express employs predictive analytics to detect potential fraud by examining transaction data. AI algorithms spot unusual patterns or activities deviating from a user’s normal spending, enabling real-time anomaly detection.
- UPS enhances delivery efficiency with predictive analytics by analyzing delivery timings, vehicle speeds, and traffic conditions to identify the most efficient delivery routes, significantly saving miles driven and fuel consumption.
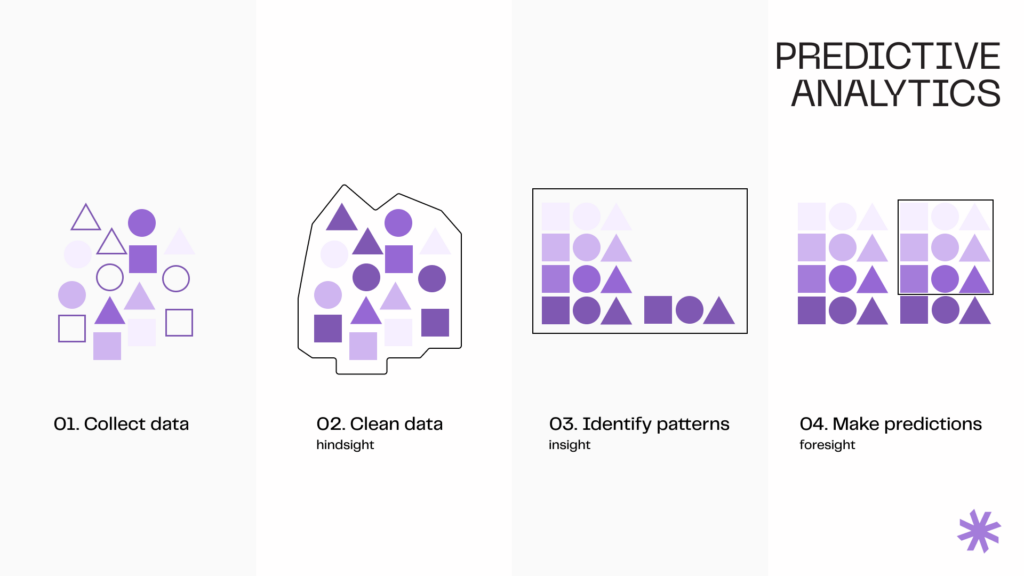
The process of creating an AI-powered predictive analytics system involves cleaning and preprocessing the data to ensure accuracy, consistency, and usability for modeling. Next, it’s crucial to understand the data’s underlying structures and patterns to select appropriate modeling techniques and features for prediction.
Further, data science engineers either create or select features depending on the prediction task to build predictive models. They train the models with prepared data to identify patterns and relationships for future predictions.
After training, models must be evaluated and validated for predictive accuracy and generalizability. This often involves using a new data set the model hasn’t seen before. Based on evaluation results, adjustments may be made to improve outcomes.
Once a model is considered accurate and reliable, it’s deployed into production to make predictions. Developers continue to monitor and periodically update the model with new data to adapt to trends or behaviors.
As you can see, data is essential for these applications at every step of development. Therefore, for predictive analytics to be effective, companies must gather sufficient relevant historical data to provide insights into future behaviors, patterns, or trends.
The power of natural language processing (NLP)
NLP AI systems are able to comprehend, interpret, and generate human language. Their evolution has been driven by advancements in machine learning, deep learning, and the availability of large and diverse datasets. One prominent example of an NLP system is ChatGPT from OpenAI.
Numerous companies leverage NLP for their operations, including:
- Google employs NLP in its search engine to grasp and interpret user queries, providing more relevant search results. NLP is also fundamental to Google Translate for language translation and Google Assistant for voice-activated commands and responses.
- Amazon relies on NLP for its Alexa virtual assistant to process and understand voice commands. NLP is also critical in Amazon’s recommendation systems, analyzing customer reviews and feedback to improve product recommendations.
- Meta (Facebook) uses NLP for content moderation by automatically detecting and flagging inappropriate content. Additionally, the company applies NLP in its Messenger platform to understand user messages and provide automated responses or suggestions.
- Zillow applies NLP in its Zestimate algorithm to understand textual descriptions of properties and incorporate this information into its home value estimation models. NLP helps in extracting valuable features from listing descriptions to improve accuracy.
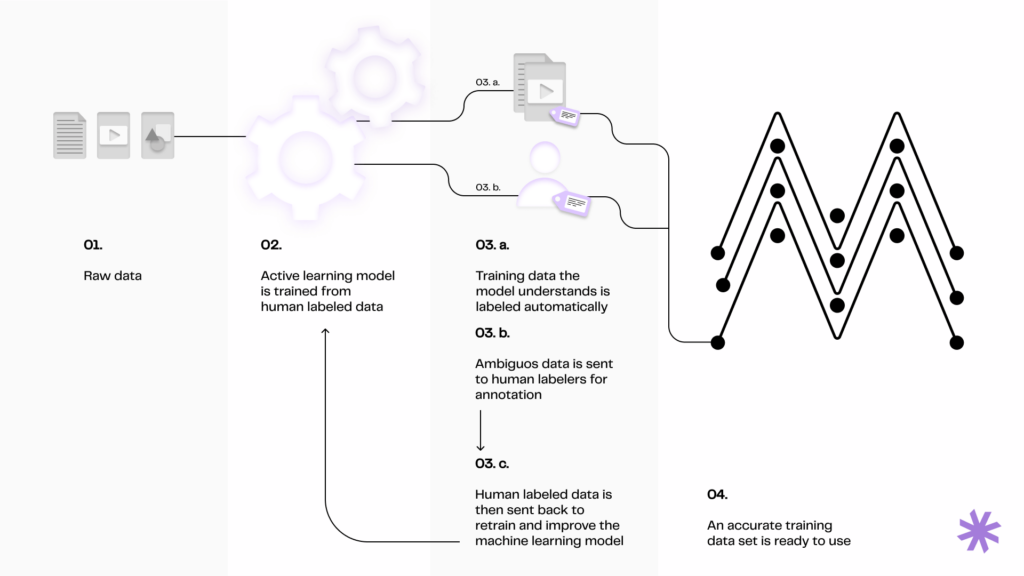
The development of NLP systems predominantly relies on machine learning models that require vast amounts of data for training. These datasets typically consist of text (or speech converted to text) that the models use to learn the intricacies of human language, including grammar, syntax, semantics, and context. For instance, a model trained for sentiment analysis would learn from a dataset of product reviews labeled with sentiments (positive, negative, neutral), enabling it to predict the sentiment of unseen reviews.
Once the NLP model is developed and trained, developers evaluate its performance on various NLP tasks using standardized datasets with known outcomes. They assess how accurately the model’s predictions align with the ground truth in these datasets.
After deployment, NLP models can continue to learn and improve by processing new incoming data. This enables them to adapt to evolving language use, including the introduction of new slang, terms, or usage patterns.
However, this adaptability also carries the risk of drifting away from their intended functions or introducing bias. Hence, ongoing human oversight and control over incoming data quality are crucial to ensure an NLP model remains accurate.
Visual data recognition
Visual data recognition systems can interpret and understand visual information from their surroundings. Notable examples of companies using AI-powered visual data recognition systems include:
- Tesla’s Autopilot system uses computer vision alongside sensors and radar to interpret the vehicle’s surroundings, enabling features like automatic lane keeping, adaptive cruise control, and self-parking. The AI system processes visual data in real time to make driving decisions.
- Pinterest offers a visual search tool that allows users to search for items or ideas using images instead of words. The AI system analyzes uploaded images to find similar items or related content within the platform.
- IBM’s Watson Health uses visual data recognition to analyze medical images like MRI scans, aiding in disease diagnosis. The AI system identifies patterns and anomalies indicative of medical conditions, assisting doctors in decision-making.
- JD.com employs visual data recognition in its warehouses to automate package sorting and handling. The system identifies package destinations through labels, enhancing efficiency and reducing errors.
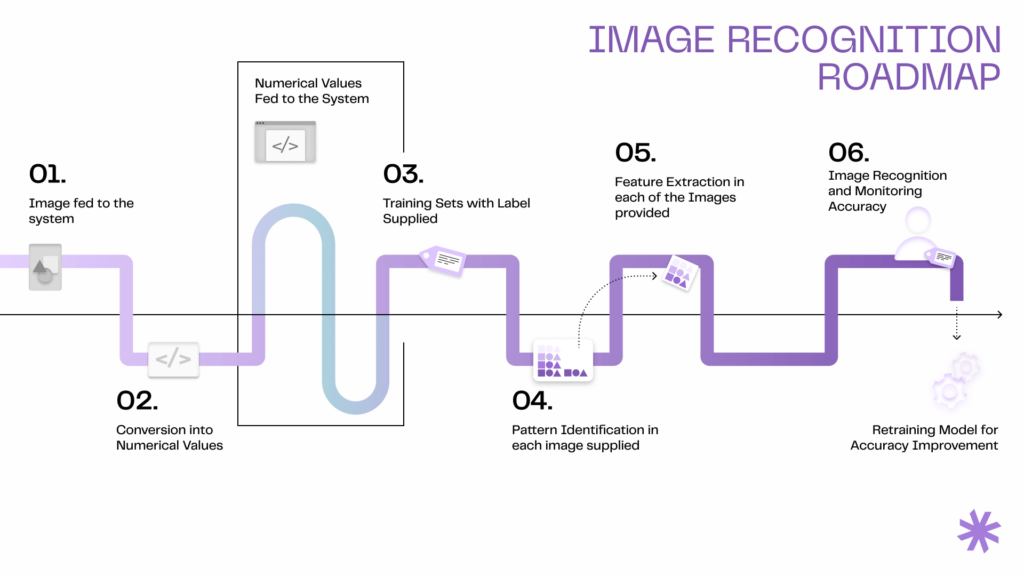
These systems heavily rely on data for training, testing, and refining their algorithms. Therefore, a large collection of images or videos is necessary to develop a visual data recognition system. This data should be labeled or annotated to indicate the presence of specific objects, features, or conditions that the system needs to recognize.
For example, an image recognition model designed to identify animals might be trained on thousands of labeled images, each indicating the contained animal. This data allows machine learning models to learn visual patterns associated with each category.
Further, data augmentation techniques are often applied to enhance the model’s ability to generalize from the training data to real-world scenarios. This involves creating variations of the training data through transformations like rotating, scaling, cropping, or altering the lighting conditions of images.
Post-training, the model is validated and tested using separate datasets to assess its accuracy, precision, recall, and other metrics. Based on testing results, model parameters are fine-tuned to improve performance.
In cases when real-world data is scarce, synthetic data generated through computer graphics or simulations can supplement the training dataset.
After deployment, visual recognition systems often require periodic updates with new data to adapt to dynamic environments, ensuring relevance and accuracy.
Unsure where to begin with AI development?
Share your concept with us, and our team of AI development specialists will provide you with a plan detailing everything necessary to create high-quality, high-performance AI software.
Contact usData challenges and solutions
Collecting data for AI development may not seem so difficult, especially when developing general-use features, such as basic image recognition software, for which there is an abundance of publicly available datasets.
However, even for relatively simple tasks involving AI, there are some pitfalls you should be aware of.
Data security
AI software development with Python frequently becomes a target for cyberattacks, which poses risks such as unauthorized access and theft. Compromises in data protection can result in financial losses, privacy breaches, and even endanger safety in cases like autonomous vehicles and healthcare systems.
To protect AI-powered software, it’s critical to implement stringent data encryption, use secure access controls, regularly update systems to fix vulnerabilities and consider using federated learning to train models locally without centralizing sensitive data.
Data privacy
AI systems are subject to strict data protection regulations, such as GDPR in Europe and CCPA in California. In order to operate AI software in these markets, developers must ensure data transparency and control for individuals, limit data collection to the essentials, anonymize data to prevent individual identification, and employ privacy-preserving methods like differential privacy, which protects individual data while gathering useful aggregate information.
Bias
Bias in AI refers to systematic and unfair discrimination against certain groups or individuals. It stems from training data or inaccuracies in system design and can lead to unfair outcomes, like biased job screening tools or less accurate facial recognition for specific ethnic groups.
To prevent bias, AI developers should curate diverse training datasets, use algorithms to detect and correct bias in data and predictions, involve multidisciplinary teams in AI development for broader perspectives, and continuously monitor and test AI systems to address new biases as they evolve.
Preparing your system for AI experimentation
High-quality data is only part of successful AI development. Your system must also be ready to support experimentation.
AI models require computing resources, flexible integrations, and the ability to evolve without disrupting core functionality. For this reason, it is often best to introduce AI components as separate services connected through APIs. This allows teams to test, refine, and replace models without affecting the stability of the entire application.
Additionally, companies should implement monitoring mechanisms to track model performance and detect data drift. Preparing your architecture for experimentation ensures that AI initiatives remain controlled, scalable, and aligned with business goals.
Summary
Digital transformation is at its peak, with even the smallest businesses using at least one software tool to guide their decision-making. AI software is pivotal in providing accurate, actionable insights, allowing businesses to distinguish themselves by offering highly relevant products and services to their customers.
Yet, the foundation of successful AI development lies in data, which is essential for the training and functioning of AI systems. The key to building a robust solution is ensuring access to sufficient, relevant data, paving the way for data-driven decisions that have a widespread impact on your organization.
Syndicode specializes in optimizing the data structuring and transformation process alongside developing impactful AI and ML-powered software. Our services enable you to identify patterns and trends within your data, offering insights that can transform your business operations.
Reach out to us to unlock the full potential of AI technology and move forward confidently in your digital transformation journey.
Frequently asked questions
-
How is data used in Artificial intelligence?

Data is crucial in AI, acting as the foundation upon which AI systems learn, make decisions, and improve over time. It’s involved in several essential processes such as training, validation, testing of models, and the continuous operation and enhancement of AI applications. AI models start their learning journey with prepared datasets, which can be both labeled and unlabeled, to recognize patterns and make predictions. Following training, these models are tested with a separate dataset they haven’t seen before to evaluate their performance and estimate how the models will perform in real-world scenarios. Moreover, AI models can use real-time or near-real-time data to make predictions or decisions across various applications, from product recommendations for online shoppers to navigating autonomous vehicles. Additionally, some AI systems are built to keep learning from new data, enabling them to adjust to new conditions continuously. Furthermore, the data generated from the AI’s operations often gets reintegrated into the system, serving to further refine and enhance the model’s accuracy and efficiency.
-
Why is data quality important in AI?
The quality of data on which AI models are trained and operated directly influences their performance, reliability, and fairness. High-quality data is characterized by its accuracy, comprehensiveness, relevance, and lack of bias. Consequently, if the training data contains errors, inaccuracies, or is not representative of real-world scenarios, the model’s predictions are prone to inaccuracies, reflecting its inability to correctly identify patterns and relationships, leading to poor performance. Additionally, poor quality data that doesn’t accurately represent the varied situations a model will encounter in real world can lead to unpredictable or erratic AI behavior. It is crucial for high-quality data to be unbiased and inclusive of diverse viewpoints and demographics to promote fairness and equity in AI outcomes. Incorporating a broad spectrum of scenarios and variations into the data also enhances the model’s ability to generalize its learning to new situations, boosting its applicability and usefulness. Furthermore, in many industries, AI systems must comply with regulatory standards governing data quality and management. High-quality data practices help ensure compliance with these standards, avoiding legal and ethical issues, especially in sensitive areas such as healthcare, finance, and law enforcement.
-
Where does AI get its data from?
AI systems draw data from various sources, depending on the application, use domain, and the specific requirements of the AI model in question. Common data sources for AI include public datasets and repositories, online and social media platforms, sensors and IoT devices, proprietary internal company data, and synthetic data. In addition, AI models, particularly generative adversarial networks (GANs), themselves can generate new data. GANs can create lifelike images, text, or other types of data, which can then be used for additional training, testing, or to enhance existing datasets.
-
How do you use data for insights?
Using data to gain insights is a multi-step process involving several stages: collecting, processing, analyzing, and interpreting data to aid decision-making, spot trends, and discover hidden patterns. The first stage is setting clear goals for data collection and analysis. Determine what you aim to learn, whether it’s understanding customer behavior, pinpointing operational inefficiencies, or forecasting future trends. Establish what successful analysis looks like. This helps shape your approach and ensures focus on the most relevant data. Next, gather data from various sources that align with your objectives. Using data from multiple sources creates a richer dataset, which might involve merging data, standardizing formats, and ensuring data consistency. Clean and prep the data to eliminate missing values, duplicates, or outliers. Transform the data into a format ready for analysis, which may include normalizing data, encoding categorical variables, or creating new features. Conduct Exploratory Data Analysis (EDA) to uncover patterns, trends, and anomalies, and to test hypotheses within your data. Then, select suitable statistical models or machine learning algorithms based on your goals and data type. If applying machine learning, train your model on a dataset segment and validate it with a different dataset to check its prediction or classification accuracy on new data. Examine the output from your statistical analysis or model predictions to extract relevant insights related to your initial questions. Summarize your findings, methodologies, and insights’ implications in a report or presentation. Consider using data visualizations to effectively communicate complex data. Finally, apply the analysis insights to guide decision-making, strategy formulation, and action plans, ensuring they align with your objectives and support overall business goals.
-
How to use AI for predictions?
Using AI to make predictions involves applying machine learning and deep learning techniques to analyze past data and forecast future events, trends, or behaviors. The process begins with defining your objectives, which could vary from аorecasting stock prices, predicting customer churn, to estimating the spread of a disease, and identifying the specific outcomes you aim to predict, along with any constraints or limitations. Proceed by gathering historical data that is relevant to your prediction goals. Prepare this data for analysis by identifying key features (variables) that impact your prediction targets. Enhance model performance by creating new features as needed. Choose a machine learning model that fits your prediction goal, data type, and the problem’s complexity. Divide your data into training and testing sets, with a common division being 80% for training and 20% for testing. If available, use a separate validation set to fine-tune hyperparameters and select the optimal model. Use the training data to train your model. Employ the validation set to adjust hyperparameters and improve the model’s performance. Test the model with your test set to assess its predictive accuracy. Based on the results, you may need to refine the model, explore different algorithms, or revisit your feature selection. Once satisfied with the model’s performance, integrate it into your application or process for real-time predictions or forecasts. Regularly monitor the model to ensure its predictions remain precise with incoming data. Be prepared to update or retrain the model with new data to sustain its accuracy.
-
Is NLP machine learning or AI?
Natural Language Processing is a branch of Artificial Intelligence that focuses on the interaction between computers and humans through natural language. NLP is made possible by a range of techniques and tools, many of which rely on machine learning to achieve their objectives. So, while NLP is fundamentally an area of AI focused on language, machine learning provides the techniques and computational methods that enable much of the advanced functionality in NLP systems today.
-
How do you use AI to read images?
Using AI to read images typically involves techniques from the field of Computer Vision, which enables computers to “see” and interpret the content of digital images and videos. The process usually relies on Deep Learning, a branch of machine learning, using Convolutional Neural Networks (CNNs) or similar architectures designed to recognize patterns and features in images. Applications of AI in image interpretation range widely, including facial recognition systems, medical image analysis, object detection and categorization within images, and transforming handwritten or printed text into digitally readable text. Developing AI systems for image reading involves several steps: defining the project’s goals, gathering and preparing the relevant data, choosing a suitable model, training and evaluating the model’s performance, and, following deployment, continuously monitoring and potentially retraining the model to maintain or improve its accuracy.